
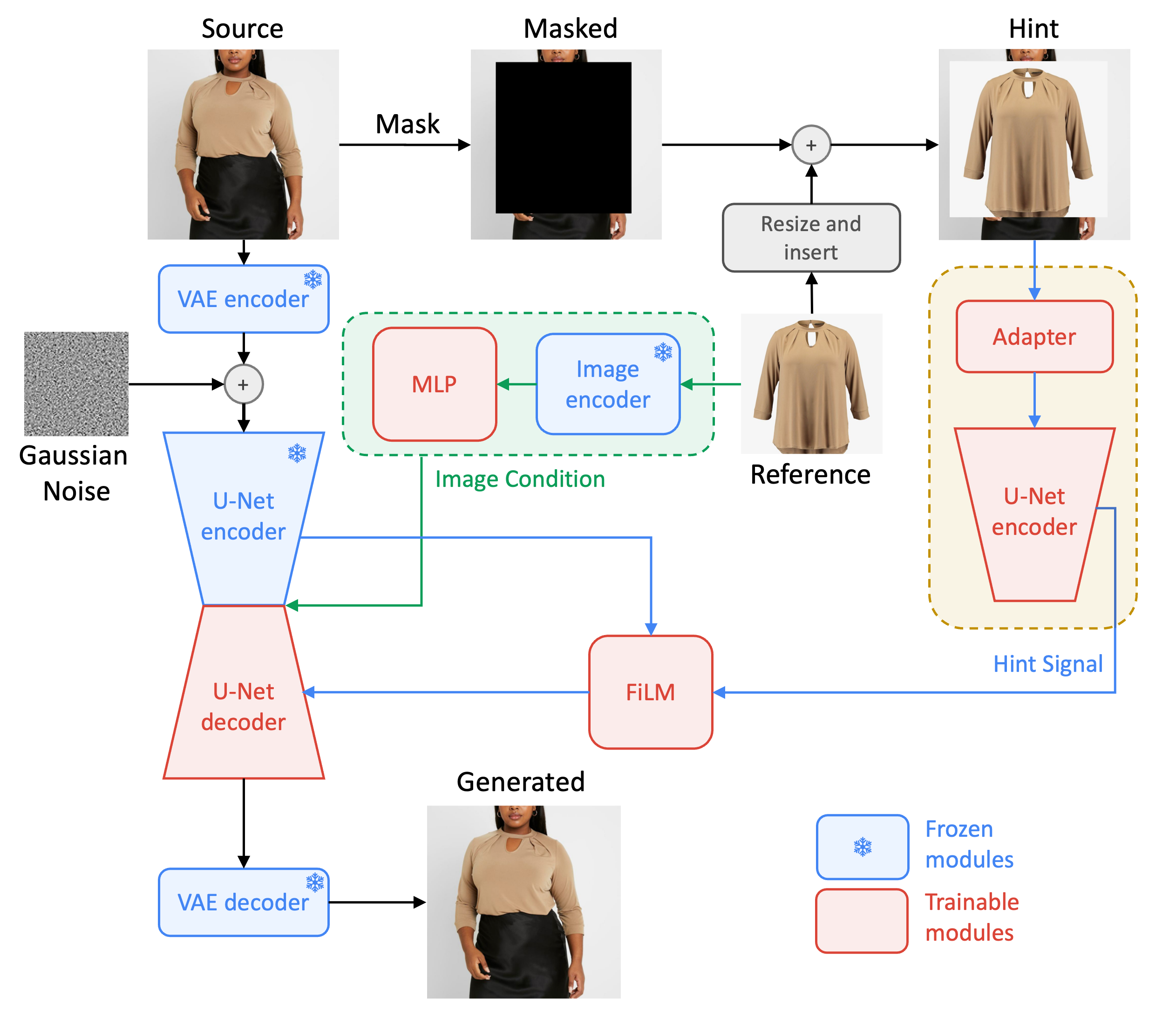
온라인 쇼핑이 성장함에 따라 구매자가 자신의 환경에서 제품을 가상으로 시각화할 수 있는 능력(우리가 "가상 체험형"으로 정의하는 현상)이 중요해졌습니다. 최근 확산 모델에는 본질적으로 월드 모델이 포함되어 있어 이를 인페인팅 컨텍스트 내에서 이 작업에 적합하게 렌더링합니다. 그러나 기존의 이미지 조절 확산 모델은 제품의 세밀한 세부 사항을 포착하지 못하는 경우가 많습니다. 이와 대조적으로 DreamPaint 와 같은 개인화 중심 모델은 항목의 세부 정보를 보존하는 데는 좋지만 실시간 애플리케이션에 최적화되어 있지 않습니다.
우리는 주어진 장면 콘텐츠에서 정확한 의미론적 조작을 보장하면서 주어진 참조 항목의 충실도가 높은 세부 정보 유지와 빠른 추론의 균형을 효율적으로 유지하는 새로운 확산 기반 이미지 조절 인페인팅 모델인 Diffuse to Choose 를 제시합니다. 우리의 접근 방식은 참조 이미지의 세밀한 특징을 기본 확산 모델의 잠재 특징 맵에 직접 통합하는 것과 참조 항목의 세부 사항을 더욱 보존하기 위한 지각 손실을 기반으로 합니다. 우리는 사내 및 공개적으로 사용 가능한 데이터 세트에 대해 광범위한 테스트를 수행했으며 Diffuse to Choose가 기존 제로 샷 확산 인페인팅 방법은 물론 DreamPaint 와 같은 소수 샷 확산 개인화 알고리즘보다 우수하다는 것을 보여주었습니다 .
https://diffuse2choose.github.io/
https://diffuse2choose.github.io/
As online shopping is growing, the ability for buyers to virtually visualize products in their settings—a phenomenon we define as "Virtual Try-All"—has become crucial. Recent diffusion models inherently contain a world model, rendering them suitable fo
diffuse2choose.github.io

'AI > pose with style' 카테고리의 다른 글
| Virtual Tryon IDM-VTON (0) | 2024.05.07 |
|---|---|
| IPADATER PLUS를 활용해 의상을 변경해보자 (0) | 2024.04.17 |
| Stablediffusion - Replacer ( try on ) (0) | 2024.01.21 |
| ReplaceAnything (0) | 2024.01.14 |
| Moore-AnimateAnyone (0) | 2024.01.14 |



댓글