
- VLOGGER는 사람의 한 장의 이미지만으로도 음성에 기반한 비디오를 생성하는 새로운 방법입니다.
- 이 방법은 1) 사람의 움직임을 3D로 표현하는 확률적 diffusion 모델과 2) 얼굴과 몸의 표현을 통해 제어가 가능한 새로운 diffusion 기반 구조로 구성되어 있습니다.
- 기존 방법과 달리 각 사람의 트레이닝이 필요없고, 얼굴 인식이나 자르기가 없어도 전체 이미지를 만들며 다양한 시나리오 (몸통이 보이거나 사람의 특성이 다양한 경우 등) 에서도 적용가능합니다.
- MENTOR라는 새로운 데이터셋을 만들었는데, 이는 기존 데이터셋보다 10배 크고 (80만 명), 다양한 제스처가 포함되어 있습니다. 이를 통해 VLOGGER의 주요 기술적 기여도를 측정했습니다.
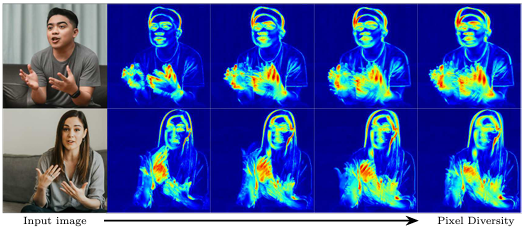
- VLOGGER는 이미지 퀄리티, 얼굴 인식 정확도, 시간적 일관성 뿐 아니라 상체 움직임까지 생성하며, 현재 사용되는 다른 방법들을 능가합니다.
- 다양한 관점에서 VLOGGER의 성능을 분석했고, 아키텍처와 MENTOR 데이터셋의 사용으로 공정하고 편향되지 않은 모델이 만들어졌음을 확인했습니다.
- 마지막으로 비디오 편집과 개인화 분야에 어떻게 적용될 수 있는지 보여줍니다.
https://enriccorona.github.io/vlogger/
VLOGGER
We propose VLOGGER, a method for text and audio-driven talking human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffus
enriccorona.github.io

'AI > Generative Video' 카테고리의 다른 글
| i2vgen-xl (0) | 2023.12.17 |
|---|---|
| DreaMoving (0) | 2023.12.17 |
| CoDeF (0) | 2023.08.20 |
| Runway Gen-2 image to video has been released! (0) | 2023.08.01 |
| RERENDER A VIDEO: ZERO-SHOT TEXT-GUIDED VIDEO-TO-VIDEO TRANSLATION (0) | 2023.06.18 |

댓글