
홈페이지 : https://ai.meta.com/blog/audiocraft-musicgen-audiogen-encodec-generative-ai-audio/
소스: https://github.com/facebookresearch/audiocraft
전문 음악가가 악기에서 단 한 음을 연주하지 않고도 새로운 작곡을 탐구할 수 있다고 상상해 보십시오. 또는 적은 예산으로 사실적인 음향 효과와 주변 소음으로 가상 세계를 채우는 인디 게임 개발자. 또는 소규모 비즈니스 소유자가 최신 Instagram 게시물에 사운드트랙을 쉽게 추가할 수도 있습니다. 이것이 AudioCraft의 약속입니다. MIDI 또는 피아노 롤이 아닌 원시 오디오 신호에 대한 교육 후 텍스트 기반 사용자 입력에서 고품질의 사실적인 오디오 및 음악을 생성하는 간단한 프레임워크입니다.
AudioCraft는 MusicGen , AudioGen 및 EnCodec 의 세 가지 모델로 구성됩니다.. Meta가 소유하고 특별히 라이선스가 부여된 음악으로 훈련된 MusicGen은 텍스트 기반 사용자 입력에서 음악을 생성하는 반면 공개 음향 효과에 대해 훈련된 AudioGen은 텍스트 기반 사용자 입력에서 오디오를 생성합니다. 오늘 우리는 개선된 버전의 EnCodec 디코더를 출시하게 되어 기쁩니다. 이 버전은 더 적은 아티팩트로 더 높은 품질의 음악을 생성할 수 있습니다. 개 짖는 소리, 자동차 경적 소리 또는 나무 바닥 위의 발소리와 같은 환경 소리 및 음향 효과를 생성할 수 있는 사전 훈련된 AudioGen 모델 및 모든 AudioCraft 모델 가중치 및 코드. 이 모델은 연구 목적과 기술에 대한 사람들의 이해를 돕기 위해 사용할 수 있습니다.
텍스트에서 오디오로 쉽게
최근 몇 년 동안 언어 모델을 포함한 생성 AI 모델은 공간 이해를 나타내는 텍스트 설명에서 기계 번역을 수행하는 텍스트 및 음성 모델에 이르기까지 다양한 이미지 및 비디오 생성에서 기계 번역 또는 텍스트 또는 음성 대화 에이전트 . 그러나 우리는 이미지, 비디오 및 텍스트에 대한 생성 AI에 대한 많은 흥분을 보았지만 오디오는 항상 약간 뒤쳐지는 것처럼 보였습니다. 거기에 약간의 작업이 있지만 매우 복잡하고 개방적이지 않아 사람들이 쉽게 가지고 놀 수 없습니다.
모든 종류의 고충실도 오디오를 생성하려면 다양한 스케일에서 복잡한 신호와 패턴을 모델링해야 합니다. 음악은 일련의 음표에서 여러 악기가 있는 글로벌 음악 구조에 이르기까지 로컬 및 장거리 패턴으로 구성되기 때문에 생성하기 가장 까다로운 오디오 유형입니다. AI로 일관된 음악을 생성하는 것은 종종 MIDI 또는 피아노 롤과 같은 상징적 표현을 사용하여 해결되었습니다. 그러나 이러한 접근 방식으로는 음악에서 발견되는 표현적 뉘앙스와 문체 요소를 완전히 파악할 수 없습니다. 보다 최근의 발전은 자기 감독 오디오 표현 학습을 활용합니다.그리고 음악을 생성하는 여러 계층적 또는 캐스케이드 모델, 고품질 오디오를 생성하는 동안 신호의 장거리 구조를 캡처하기 위해 원시 오디오를 복잡한 시스템에 공급합니다. 그러나 우리는 이 분야에서 더 많은 일을 할 수 있다는 것을 알고 있었습니다.
AudioCraft 모델 제품군은 장기적으로 일관성 있는 고품질 오디오를 생성할 수 있으며 자연스러운 인터페이스를 통해 쉽게 상호 작용할 수 있습니다. AudioCraft를 사용하면 현장에서의 이전 작업과 비교하여 오디오를 위한 생성 모델의 전체 디자인을 단순화하여 사람들에게 Meta가 지난 몇 년 동안 개발해 온 기존 모델로 플레이할 수 있는 전체 레시피를 제공하는 동시에 한계를 뛰어넘을 수 있는 권한을 부여합니다. 그리고 자체 모델을 개발합니다.
AudioCraft는 음악과 사운드 생성 및 압축 작업을 모두 같은 장소에서 수행합니다. 구축 및 재사용이 쉽기 때문에 더 나은 사운드 생성기, 압축 알고리즘 또는 음악 생성기를 구축하려는 사람들은 동일한 코드 기반에서 모든 작업을 수행하고 다른 사람들이 수행한 것을 기반으로 구축할 수 있습니다.
그리고 모델을 단순하게 만드는 데 많은 작업이 들어가는 동안 팀은 AudioCraft가 최신 기술을 지원할 수 있도록 하기 위해 똑같이 노력했습니다. 사람들은 우리 모델을 쉽게 확장하고 연구를 위한 사용 사례에 맞게 조정할 수 있습니다. 사람들에게 모델에 대한 액세스 권한을 부여하여 필요에 따라 조정할 수 있도록 하면 거의 무한한 가능성이 있습니다. 이것이 바로 우리가 이 모델군으로 하고자 하는 것입니다. 사람들에게 작업을 확장할 수 있는 권한을 부여하는 것입니다.
오디오 생성에 대한 간단한 접근 방식
원시 오디오 신호에서 오디오를 생성하는 것은 매우 긴 시퀀스를 모델링해야 하므로 까다롭습니다. 44.1kHz(음악 녹음의 표준 품질)로 샘플링된 몇 분 분량의 일반적인 음악 트랙은 수백만 개의 타임스텝으로 구성됩니다. 이에 비해 Llama 및 Llama 2와 같은 텍스트 기반 생성 모델에는 샘플당 수천 개의 타임스텝을 나타내는 하위 단어로 처리된 텍스트가 제공됩니다.
이 문제를 해결하기 위해 음악 샘플에 대한 새로운 고정 "어휘"를 제공하는 EnCodec 신경 오디오 코덱을 사용하여 원시 신호에서 개별 오디오 토큰을 학습합니다 . 그런 다음 EnCodec의 디코더를 사용하여 토큰을 오디오 공간으로 다시 변환할 때 이러한 개별 오디오 토큰을 통해 자동 회귀 언어 모델을 훈련하여 새로운 토큰과 새로운 사운드 및 음악을 생성할 수 있습니다.
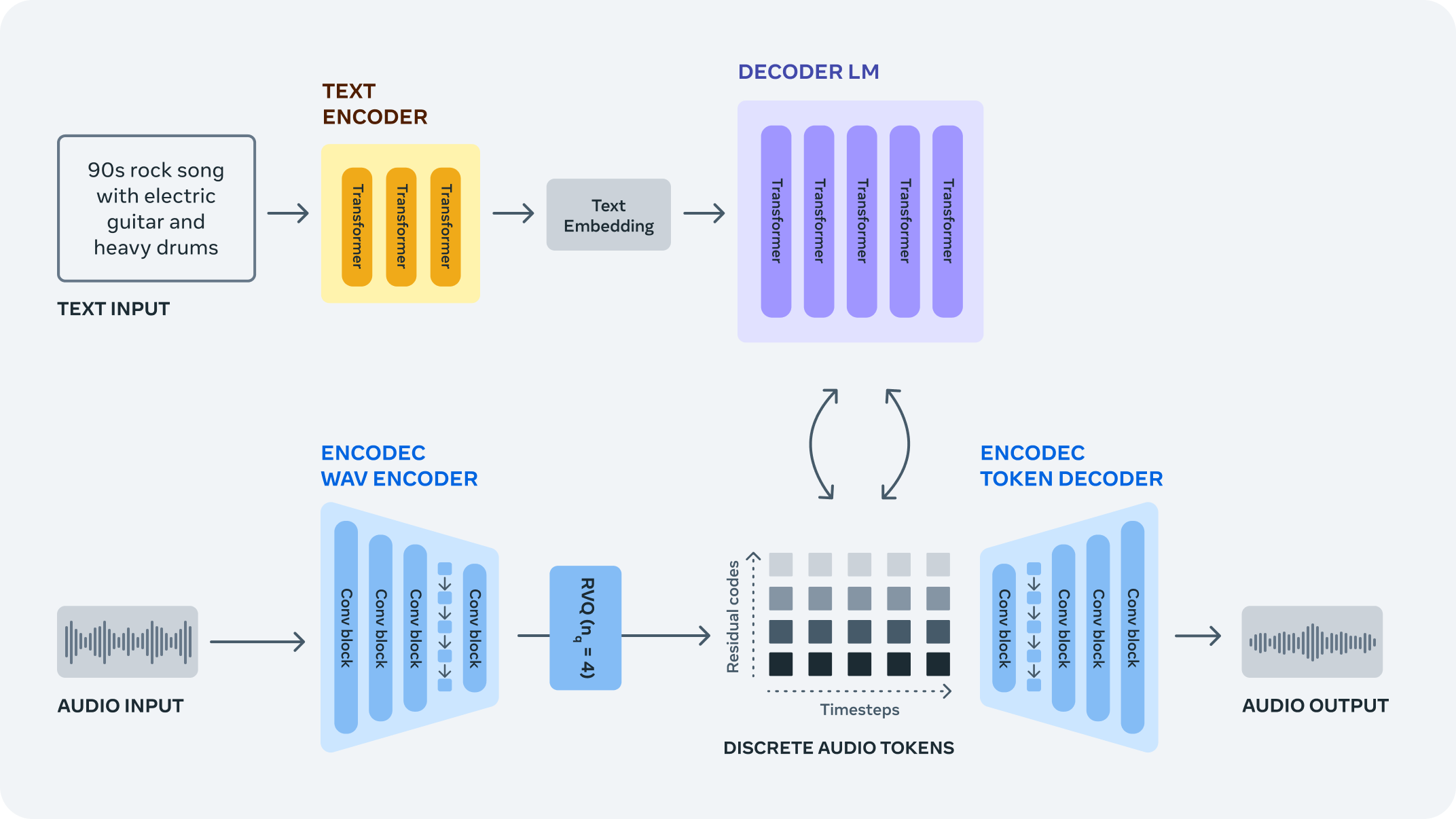
파형에서 오디오 토큰 학습
EnCodec은 모든 종류의 오디오를 압축하고 원래 신호를 충실도로 재구성하도록 특별히 훈련된 손실 신경 코덱입니다. 고정된 어휘를 사용하여 오디오 토큰의 여러 병렬 스트림을 생성하는 잔여 벡터 양자화 병목 현상이 있는 자동 인코더로 구성됩니다. 서로 다른 스트림은 오디오 파형의 서로 다른 수준의 정보를 캡처하므로 모든 스트림에서 높은 충실도로 오디오를 재구성할 수 있습니다.
오디오 언어 모델 교육
그런 다음 단일 자동 회귀 언어 모델을 사용하여 EnCodec에서 오디오 토큰을 재귀적으로 모델링합니다. 우리는 병렬 토큰 스트림의 내부 구조를 활용하는 간단한 접근 방식을 소개하고 단일 모델과 우아한 토큰 인터리빙 패턴을 통해 우리의 접근 방식이 오디오 시퀀스를 효율적으로 모델링하고 동시에 오디오의 장기적인 종속성을 캡처하고 다음을 허용함을 보여줍니다. 고품질 사운드를 생성합니다.
'AI > Music' 카테고리의 다른 글
| deepmind_DreamTrack_Music AI Tools (0) | 2023.11.20 |
|---|---|
| Stable Audio (0) | 2023.09.17 |
| 작곡 (0) | 2023.06.05 |
| TTS (0) | 2023.05.01 |
| SoundRaw (0) | 2023.04.06 |


댓글